
【导读】学术上有个概念是“传声器阵列”,主要由一定数目的声学传感器组成,用来对声场的空间特性进行采样并处理的系统。而这篇文章讲到的麦克风阵列是其中一个狭义概念,特指应用于语音处理的按一定规则排列的多个麦克风系统,也可以简单理解为2个以上麦克风组成的录音系统。
亚马逊Echo和谷歌Home争奇斗艳,除了云端服务,他们在硬件上到底有哪些差异?我们先将Echo和Home两款音箱拆开来看,区别最大的还是麦克风阵列技术。Amazon Echo采用的是环形6+1麦克风阵列,而Google Home(包括Surface Studio)只采用了2麦克风阵列。这种差异我们在文章《对比Amazon Echo,Google Home为何只采用了2个麦克风?》做了探讨。但是好多朋友私信咨询,因此这里想稍微深入谈谈麦克风阵列技术,以及智能语音交互设备到底应该选用怎样的方案。
什么是麦克风阵列技术?
学术上有个概念是“传声器阵列”,主要由一定数目的声学传感器组成,用来对声场的空间特性进行采样并处理的系统。而这篇文章讲到的麦克风阵列是其中一个狭义概念,特指应用于语音处理的按一定规则排列的多个麦克风系统,也可以简单理解为2个以上麦克风组成的录音系统。
麦克风阵列一般来说有线形、环形和球形之分,严谨的应该说成一字、十字、平面、螺旋、球形及无规则阵列等。至于麦克风阵列的阵元数量,也就是麦克风数量,可以从2个到上千个不等。这样说来,麦克风阵列真的好复杂,别担心,复杂的麦克风阵列主要应用于工业和国防领域,消费领域考虑到成本会简化很多。

为什么需要麦克风阵列?
消费级麦克风阵列的兴起得益于语音交互的市场火热,主要解决远距离语音识别的问题,以保证真实场景下的语音识别率。这涉及了语音交互用户场景的变化,当用户从手机切换到类似Echo智能音箱或者机器人的时候,实际上麦克风面临的环境就完全变了,这就如同两个人窃窃私语和大声嘶喊的区别。
前几年,语音交互应用最为普遍的就是以Siri为代表的智能手机,这个场景一般都是采用单麦克风系统。单麦克风系统可以在低噪声、无混响、距离声源很近的情况下获得符合语音识别需求的声音信号。但是,若声源距离麦克风距离较远,并且真实环境存在大量的噪声、多径反射和混响,导致拾取信号的质量下降,这会严重影响语音识别率。而且,单麦克风接收的信号,是由多个声源和环境噪声叠加的,很难实现各个声源的分离。这样就无法实现声源定位和分离,这很重要,因为还有一类声音的叠加并非噪声,但是在语音识别中也要抑制,就是人声的干扰,语音识别显然不能同时识别两个以上的声音。
显然,当语音交互的场景过渡到以Echo、机器人或者汽车为主要场景的时候,单麦克风的局限就凸显出来。为了解决单麦克风的这些局限性,利用麦克风阵列进行语音处理的方法应时而生。麦克风阵列由一组按一定几何结构(常用线形、环形)摆放的麦克风组成,对采集的不同空间方向的声音信号进行空时处理,实现噪声抑制、混响去除、人声干扰抑制、声源测向、声源跟踪、阵列增益等功能,进而提高语音信号处理质量,以提高真实环境下的语音识别率。
事实上,仅靠麦克风阵列也很难保证语音识别率的指标。麦克风阵列还仅是物理入口,只是完成了物理世界的声音信号处理,得到了语音识别想要的声音,但是语音识别率却是在云端测试得到的结果,因此这两个系统必须匹配在一起才能得到最好的效果。不仅如此,麦克风阵列处理信号的质量还无法定义标准。因为当前的语音识别基本都是深度学习训练的结果,而深度学习有个局限就是严重依赖于输入训练的样本库,若处理后的声音与样本库不匹配则识别效果也不会太好。从这个角度应该非常容易理解,物理世界的信号处理也并非越是纯净越好,而是越接近于训练样本库的特征越好,即便这个样本库的训练信号很差。显然,这是一个非常难于实现的过程,至少要声学处理和深度学习的两个团队配合才能做好这个事情,另外声学信号处理这个层次输出的信号特征对语义理解也非常重要。看来,小小的麦克风阵列还真的不是那么简单,为了更好地显示这种差别,我们测试了某语音识别引擎在单麦克风和四麦克风环形阵列的识别率对比。另外也要提醒,语音识别率并非只有一个WER指标,还有个重要的虚警率指标,稍微有点声音就乱识别也不行,另外还要考虑阈值的影响,这都是麦克风阵列技术中的陷阱。

麦克风阵列的关键技术
消费级的麦克风阵列主要面临环境噪声、房间混响、人声叠加、模型噪声、阵列结构等问题,若使用到语音识别场景,还要考虑针对语音识别的优化和匹配等问题。为了解决上述问题,特别是在消费领域的垂直场景应用环境中,关键技术就显得尤为重要。
噪声抑制:语音识别倒不需要完全去除噪声,相对来说通话系统中需要的技术则是噪声去除。这里说的噪声一般指环境噪声,比如空调噪声,这类噪声通常不具有空间指向性,能量也不是特别大,不会掩盖正常的语音,只是影响了语音的清晰度和可懂度。这种方法不适合强噪声环境下的处理,但是应付日常场景的语音交互足够了。
混响消除:混响在语音识别中是个蛮讨厌的因素,混响去除的效果很大程度影响了语音识别的效果。我们知道,当声源停止发声后,声波在房间内要经过多次反射和吸收,似乎若干个声波混合持续一段时间,这种现象叫做混响。混响会严重影响语音信号处理,比如互相关函数或者波束主瓣,降低测向精度。

回声抵消:严格来说,这里不应该叫回声,应该叫“自噪声”。回声是混响的延伸概念,这两者的区别就是回声的时延更长。一般来说,超过100毫秒时延的混响,人类能够明显区分出,似乎一个声音同时出现了两次,我们就叫做回声,比如天坛著名的回声壁。实际上,这里所指的是语音交互设备自己发出的声音,比如Echo音箱,当播放歌曲的时候若叫Alexa,这时候麦克风阵列实际上采集了正在播放的音乐和用户所叫的Alexa声音,显然语音识别无法识别这两类声音。回声抵消就是要去掉其中的音乐信息而只保留用户的人声,之所以叫回声抵消,只是延续大家的习惯而已,其实是不恰当的。
声源测向:这里没有用声源定位,测向和定位是不太一样的,而消费级麦克风阵列做到测向就可以了,没必要在这方面投入太多成本。声源测向的主要作用就是侦测到与之对话人类的声音以便后续的波束形成。声源测向可以基于能量方法,也可以基于谱估计,阵列也常用TDOA技术。声源测向一般在语音唤醒阶段实现,VAD技术其实就可以包含到这个范畴,也是未来功耗降低的关键研究内容。
波束形成:波束形成是通用的信号处理方法,这里是指将一定几何结构排列的麦克风阵列的各麦克风输出信号经过处理(例如加权、时延、求和等)形成空间指向性的方法。波束形成主要是抑制主瓣以外的声音干扰,这里也包括人声,比如几个人围绕Echo谈话的时候,Echo只会识别其中一个人的声音。
阵列增益:这个比较容易理解,主要是解决拾音距离的问题,若信号较小,语音识别同样不能保证,通过阵列处理可以适当加大语音信号的能量。
模型匹配:这个主要是和语音识别以及语义理解进行匹配,语音交互是一个完整的信号链,从麦克风阵列开始的语音流不可能割裂的存在,必然需要模型匹配在一起。实际上,效果较好的语音交互专用麦克风阵列,通常是两套算法,一套内嵌于硬件实时处理,另外一套服务于云端匹配语音处理。
麦克风阵列的技术趋势
语音信号其实是不好处理的,我们知道信号处理大多基于平稳信号的假设,但是语音信号的特征参数均是随时间而变化的,是典型的非平稳态过程。幸运的是语音信号在一个较短时间内的特性相对稳定(语音分帧),因而可以将其看作是一个准稳态过程,也就是说语音信号具有短时平稳的特性,这才能用主流信号处理方法对其处理。从这点来看,麦克风阵列的基本原理和模型方面就存在较大的局限,也包括声学的非线性处理(现在基本忽略非线性效应),因此基础研究的突破才是未来的根本。希望能有更多热爱人工智能的学生关注声学,报考我们中科院声学所。
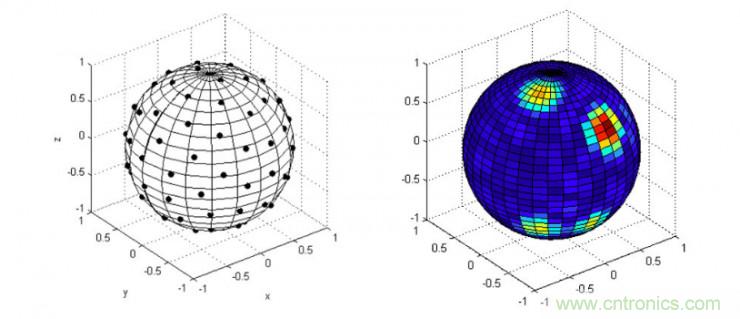
另外一个趋势就是麦克风阵列的小型化,麦克风阵列受制于半波长理论的限制,现在的口径还是较大,声智科技现在可以做到2cm-8cm的间距,但是结构布局仍然还是限制了ID设计的自由性。很多产品采用2个麦克风其实并非成本问题,而是ID设计的考虑。实际上,借鉴雷达领域的合成孔径方法,麦克风阵列可以做的更小,而且这种方法已经在军工领域成熟验证,移植到消费领域只是时间问题。
还有一个趋势是麦克风阵列的低成本化,当前无论是2个麦克风还是4、6个麦克风阵列,成本都是比较高的,这影响了麦克风阵列的普及。低成本化不是简单的更换芯片器件,而是整个结构的重新设计,包括器件、芯片、算法和云端。这里要强调一下,并非2个麦克风的阵列成本就便宜,实际上2个和4个麦克风阵列的相差不大,2个麦克风阵列的成本也要在60元左右,但是这还不包含进行回声抵消的硬件成本,若综合比较,实际上成本相差不大。特别是今年由于新技术的应用,多麦克风阵列的成本下降非常明显。
再多说一个趋势就是多人声的处理和识别,其中典型的是鸡尾酒会效应,人的耳朵可以在嘈杂的环境中分辨想要的声音,并且能够同时识别多人说话的声音。现在的麦克风阵列和语音识别还都是单人识别模式,距离多人识别的目标还很远。前面提到了现在的算法思想主要是“抑制”,而不是“利用”,这实际上就是人为故意简化了物理模型,说白了就是先拿“软柿子”下手,因此语音交互格局已定的说法经不起推敲,对语音交互的认识和探究应该说才刚刚开始,基础世界的探究很可能还会出现诺奖级的成果。若展望的更远一些,则是物理学的进展和人工智能的进展相结合,可能会颠覆当前的声学信号处理以及语音识别方法。
如何选用麦克风阵列?
当前成熟的麦克风阵列的主要包括:讯飞的2麦、4麦和6麦方案,思必驰的6+1麦方案,云知声(科胜讯)的2麦方案,以及声智科技的单麦、2麦阵列、4(+1)麦阵列、6(+1)麦阵列和8(+1)麦阵列方案,其他家也有麦克风阵列的硬件方案,但是缺乏前端算法和云端识别的优化。由于各家算法原理的不同,有些阵列方案可以由用户自主选用中间的麦克风,这样更利于用户进行ID设计。其中,2个以上的麦克风阵列又分为线形和环形两种主流结构,而2麦的阵列则又有Broadside和Endfire两种结构,限于篇幅我们以后的文章再展开叙述。
如此众多的组合,那么厂商该如何选择这些方案呢?首先还是要看产品定位和用户场景。若定位于追求性价比的产品,其实就不用考虑麦克风阵列方案,就直接采用单麦方案,利用算法进行优化,也可实现噪声抑制和回声抵消,能够保证近场环境下的语音识别率,而且成本绝对要低很多。至于单麦语音识别的效果,可以体验下采用声智科技单麦识别算法的360儿童机器人。
但是若想更好地去除部分噪声,可以选用2麦方案,但是这种方案比较折衷,主要优点就是ID设计简单,在通话模式(也就是给人听)情况下可以去除某个范围内的噪音。但是语音识别(也就是给机器听)的效果和单麦的效果却没有实质区别,成本相对也比较高,若再考虑语音交互终端必要的回声抵消功能,成本还要上升不少。2麦方案最大的弊端还是声源定位的能力太差,因此大多是用在手机和耳机等设备上实现通话降噪的效果。这种降噪效果可以采用一个指向性麦克风(比如会议话筒)来模拟,这实际上就是2麦的Endfire结构,也就是1个麦克风通过原理设计模拟了2个麦克风的功能。指向性麦克风的不方便之处就是ID设计需要前后两个开孔,这很麻烦,例如叮咚1代音箱采用的就是这种指向性麦克风方案,因此采用了周边一圈的悬空设计。
若希望产品能适应更多用户场景,则可以类似亚马逊Echo一样直接选用4麦以上的麦克风阵列。这里简单给个参考,机器人一般4个麦克风就够了,音箱建议还是选用6个以上麦克风,至于汽车领域,最好是选用其他结构形式的麦克风阵列,比如分布式阵列。
多个麦克风阵列之间的成本差异现在正在变小,估计明年的成本就会相差不大。这是趋势,新兴的市场刚开始成本必然偏高,但随着技术进步和规模扩张,成本会快速走低,因此新兴产品在研发阶段倒是不需要太过纠结成本问题,用户体验才是核心的关键。
本文作者陈孝良,工学博士,声智科技创始人。
推荐阅读:
推荐阅读:

