

【导读】本设计实例以数学公式和文字对置信区间进行了基本定义,工程师能够以数学的方式正确表达估计的确定性。同时还描述了观察时间将如何影响观察到的误码与预期误码之间的关系,以及如何影响BER估计的精度。
最近我对为数众多的年轻工程师感到担忧,他们在大学里似乎没有学过应用概率课程,不知道如何量化估计的确定性。高速串行通信需要估计某条通信链路的误码率(BER),并量化该估计的置信度。我听到越来越多的年轻工程师这样说:
“好吧,我很肯定这条通信链路的误码率低于1E-12,”或者更糟糕的,“我对给你的BER估计值有99%的把握。”
但他们对声称的99%常常又没有任何依据。这个数字非常吸引人,因为它显得非常有把握,同时又留了1%的退路以便在事情出现偏差时有合理的借口。记住,这种营销式的思路不应该属于一个合格的工程师!
置信区间
首先我们来看一下置信区间的精确数学定义:
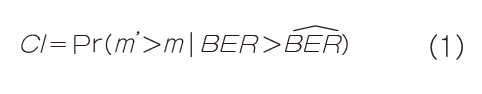
其中m’是一个可变的整数,m是实际观察到的误码数,BER是链路的实际误码率, 是估计值。 公式1用文字描述就是:“如果BER比设想的糟,那么估计的置信度就是本应观察到更多误码的概率。”
二项式分布
公式2的二项式分布定义了在已知任一比特出错概率p的条件下,在一定比特数n中观察到一定误码数m的概率。

公式2完全正确,但并不实用,因为n!通常很大,大多数数字计算器或计算机都无法处理。因此我们必须找出机器能够处理的近似公式。
泊松分布
在实际的串行通信中,假设链路设计得非常好,公式2中的m和p值一般都很小,但n很大。在这种情况下,我们可以做以下两次简化近似:
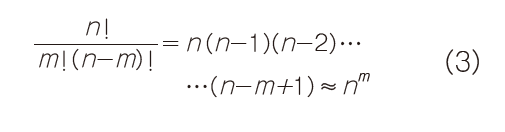
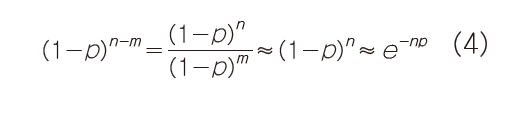
我们知道:

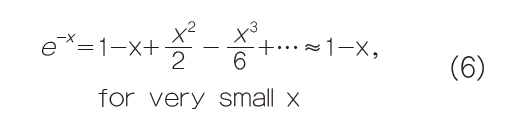
将这两个公式代入公式2就得到著名的泊松分布。
值得注意的是,公式7中不再有任何大的阶乘项,因而用数字计算机进行计算成为可能。

置信区间与无误码观察时间
假定我们看到一条处理n比特不出错的链路,利用P(m)表达式,可以对公式1进行评估。直接将公式1进行扩展得到:
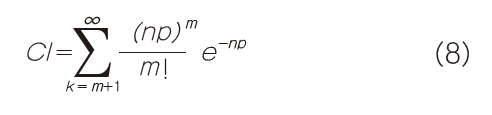
虽然通过代数技巧可以得到这些无限和的诸多封闭解,但这并非其中的一个。我们很幸运,因为可以利用如下的概率公理:

该公式表明,一个事件发生的概率等于1减去其补发生的概率。这样公式8可以改写为:
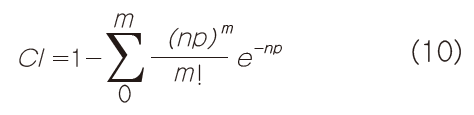
由于m的值几乎总是很小,所以公式10对设计良好的串行通信链路来说通常都是可跟踪的。在这个特定案例(无误码观察时间)中,m=0,并且:

表1针对几个不同的数值np给出了置信区间的计算结果。数值np可以被想象为无误码观察时间,归一化为UI/ ,其中UI是单位间隔。换句话说,如果我们估计链路的BER为1E-12,那么np=1意味着我们观察到1E12个比特,np=5意味着我们观察到5E12个比特。
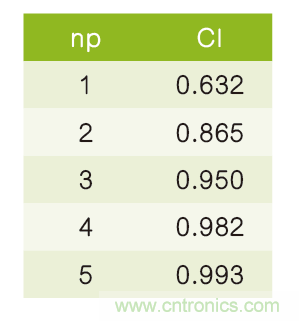
表1:置信区间和无误码观察间隔的关系。
从表中的数据可以看出,只有当无误码观察间隔达到5E12个比特,才可以断言一条链路以等于或小于1E-12的BER运行的确定性高于99%。
有误码的置信区间
如果我们增大观察间隔会发生什么?如果观察间隔足够大,我们会看到很少的误码。这对置信区间有什么影响呢?在研究这个问题之前,让我们先看看另一个问题:在表1所示的每一个案例中,我们希望观察到多少误码?
下面的数学公式可以精确地定义随机实验的期望输出结果:

其中n是完成的试验次数,px是任何一次试验成功的概率。在我们的案例中,“成功”意味着捕捉到一个误码。从公式12来看,不管观察到的误码数是多少,我们的期望值就是观察到的比特数乘以任何一个比特出错的概率。它同时表明,表1中的数值np就是我们期望观察到的误码数。
接下来让我们用更多的数据来丰富表1,如表2所示。
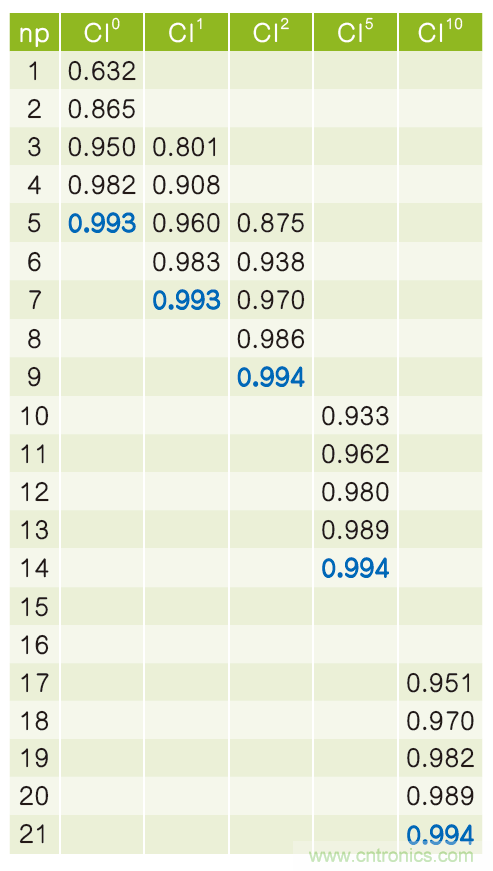
表2:观察到的误码数不同时置信区间与观察时间的比较。
现在我们给CI一个数字上标,表示观察到的误码数。对每一列CIN,蓝色粗体字代表最小观察时间,它将产生一个大于99%的置信区间。注意,观察时间的单位是期望误码数。表3列出了期望误码数和实际观察到的误码数,以及两者的比值(观察值/期望值):
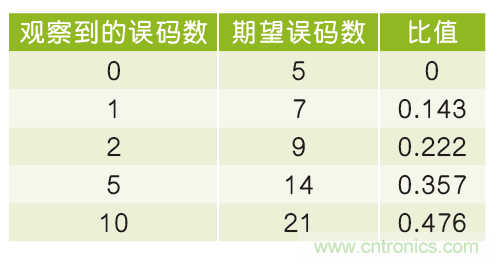
表3:不同观察时间下观察到的误码数与期望误码数之比。
趋势很明显:如果延长观察时间并接受更多观察到的误码,允许观察到的误码数会越来越接近期望值,而在BER估计中仍能提供大于99%的置信度。这与我们的直觉一致,若是能将观察时间无限延长,我们应该能够精确地观察到期望的误码数。
精度
延长观察时间的另一个好处是能够提高BER估计的精度。为了定量地进行讨论,我们需要确定一下“精确”的具体含义。因此,我们为BER估计的置信区间选择了一个有用的范围:70%到99%。
如果置信区间涉及的BER估计范围更小,就需要将特定的观察定义得更“精确”。我们一般会说:“我们不信任低于70%的置信区间,也不在意置信区间比99%高多少,只要够高就行。”
图1显示了在不同的观察时间下,置信区间是如何随BER估计变化的。观察时间已经被归一化,这样对于每一个观察到的误码数,1E-12 BER估计中的置信度就非常接近99%。从这张图可以清楚地看到,随着观察时间(和观察到的误码数)的增加,曲线有效区域的倾斜度也随之增加。图2对此进行了量化,将BER估计的有用范围作为观察时间的函数绘成了曲线。
随着观察时间接近无限,你可以想象这个极限:“CI与BER”曲线变成完美的阶梯函数,有用的BER估计范围趋于0,我们在不确定性为零的条件下得到了一个完全精确的BER估计。
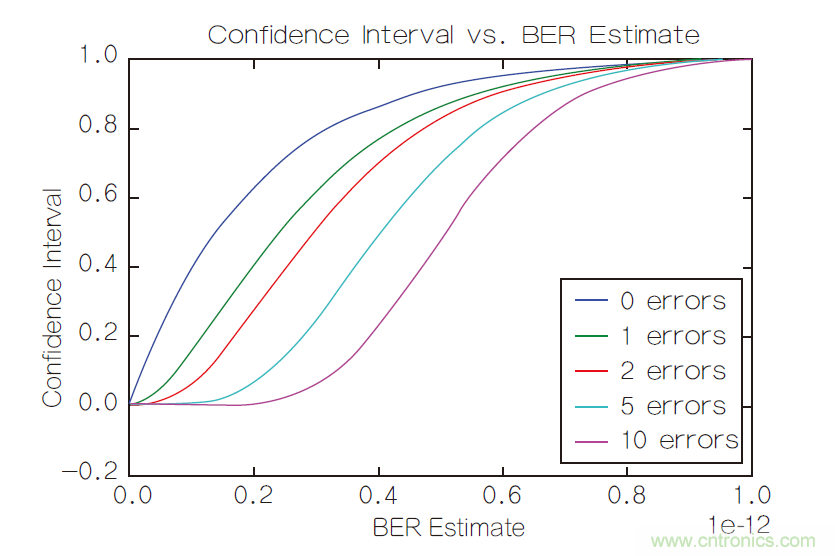
图1:不同观察时间下置信区间随BER估计的变化。
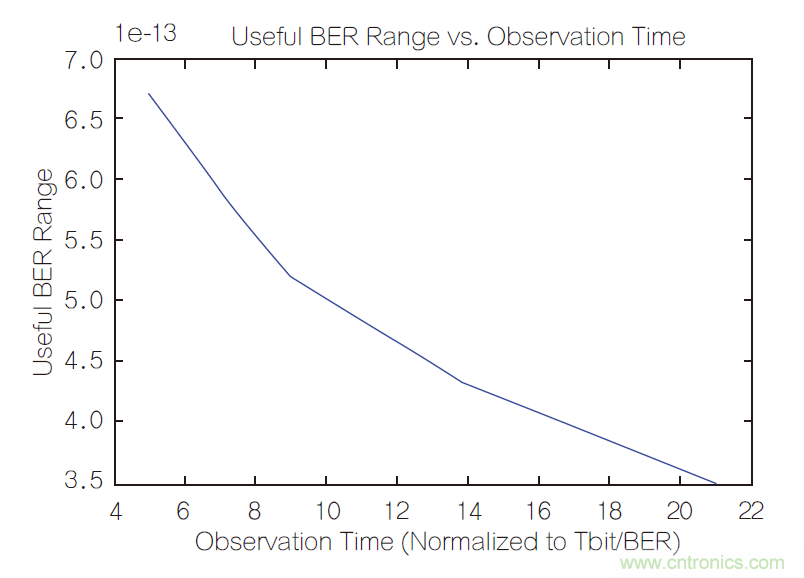
图2:随着观察时间的延长,有用的BER范围将缩小。
总结
置信区间让我们可以量化链路BER估计的确定性。对串行通信链路设计师来说这是必不可少的工具,它能帮助我们以定量的方式跟其他工程师谈论永远不具有完全确定性的事件,这对于任何一个严肃的工程讨论都特别重要。“我很肯定”这样的表达不适合工程师,最好留给营销人员推广和辩护使用。
使用文中介绍的置信区间的数学定义,你可以正确地向其他工程师表达估计的确定性。我还用文字说明了置信区间的含义,理由有二:
- 你可以欣赏工程学理论的进步;
- 你可以将置信区间的基本思想应用到串行通信链路设计以外的学科中去。
文章以数学公式和文字对置信区间进行了基本定义,还展示了观察时间如何影响观察到的误码和期望误码之间的关系以及BER估计的精度。希望这些已经引起你的兴趣,激励你继续探索工程学的发展。
本文转载自电子技术设计。
推荐阅读:

