
【导读】前文说过,根据有限的训练集,去适应无限的测试集,当然训练集容量越大效果就越好。但是,训练集如果很大,那么每次都根据全部数据执行梯度下降计算量就太大了。此时,我们选择每次只取全部训练集中的一小部分(究竟多少,一般根据内存和计算量而定),执行梯度下降,不断的迭代,根据经验一样可以快速地把梯度降下来。这就是随机梯度下降。
三、梯度的下降(下)
前文的梯度下降法只能对f函数的w权重进行调整,而上文中我们说过实际是多层函数套在一起,例如f1(f2(x;w2);w1),那么怎么求对每一层函数输入的导数呢?这也是所谓的反向传播怎样继续反向传递下去呢?这就要提到链式法则。其实质为,本来y对x的求导,可以通过引入中间变量z来实现,如下图所示:
这样,y对x的导数等价于y对z的导数乘以z对x的偏导。当输入为多维时则有下面的公式:
如此,我们可以得到每一层函数的导数,这样可以得到每层函数的w权重应当调整的步长,优化权重参数。
由于函数的导数很多,例如resnet等网络已经达到100多层函数,所以为区别传统的机器学习,我们称其为深度学习。
深度学习只是受到神经科学的启发,所以称为神经网络,但实质上就是上面提到的多层函数前向运算得到分类值,训练时根据实际标签分类取损失函数最小化后,根据随机梯度下降法来优化各层函数的权重参数。人脸识别也是这么一个流程。以上我们初步过完多层函数的参数调整,但函数本身应当如何设计呢?
四、基于CNN卷积神经网络进行人脸识别
我们先从全连接网络谈起。Google的TensorFlow游乐场里可以直观的体验全连接神经网络的威力,这是游乐场的网址:http://playground.tensorflow.org/,浏览器里就可以做神经网络训练,且过程与结果可视化。如下图所示:
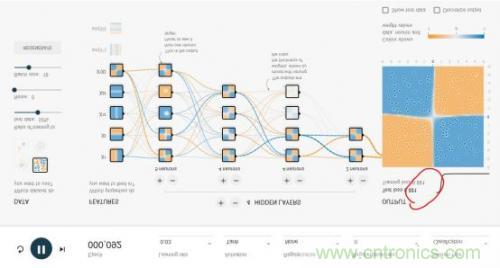
这个神经网络游乐场共有1000个训练点和1000个测试点,用于对4种不同图案划分出蓝色点与黄色点。DATA处可选择4种不同图案。
整个网络的输入层是FEATURES(待解决问题的特征),例如x1和x2表示垂直或者水平切分来划分蓝色与黄色点,这是最容易理解的2种划分点的方法。其余5种其实不太容易想到,这也是传统的专家系统才需要的,实际上,这个游乐场就是为了演示,1、好的神经网络只用最基本的x1,x2这样的输入层FEATURES就可以完美的实现;2、即使有很多种输入特征,我们其实并不清楚谁的权重最高,但好的神经网络会解决掉这个问题。
隐层(HIDDEN LAYERS)可以随意设置层数,每个隐层可以设置神经元数。实际上神经网络并不是在计算力足够的情况下,层数越多越好或者每层神经元越多越好。好的神经网络架构模型是很难找到的。本文后面我们会重点讲几个CNN经典网络模型。然而,在这个例子中,多一些隐层和神经元可以更好地划分。
epoch是训练的轮数。红色框出的loss值是衡量训练结果的最重要指标,如果loss值一直是在下降,比如可以低到0.01这样,就说明这个网络训练的结果好。loss也可能下降一会又突然上升,这就是不好的网络,大家可以尝试下。learning rate初始都会设得高些,训练到后面都会调低些。Activation是激励函数,目前CNN都在使用Relu函数。
了解了神经网络后,现在我们回到人脸识别中来。每一层神经元就是一个f函数,上面的四层网络就是f1(f2(f3(f4(x))))。然而,就像上文所说,照片的像素太多了,全连接网络中任意两层之间每两个神经元都需要有一次计算。特别之前提到的,复杂的分类依赖于许多层函数共同运算才能达到目的。当前的许多网络都是多达100层以上,如果每层都有3*100*100个神经元,可想而知计算量有多大!于是CNN卷积神经网络应运而生,它可以在大幅降低运算量的同时保留全连接网络的威力。
CNN认为可以只对整张图片的一个矩形窗口做全连接运算(可称为卷积核),滑动这个窗口以相同的权重参数w遍历整张图片后,可以得到下一层的输入,如下图所示:
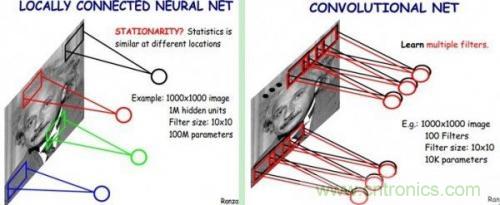
CNN中认为同一层中的权重参数可以共享,因为同一张图片的各个不同区域具有一定的相似性。这样原本的全连接计算量过大问题就解决了,如下图所示:

结合着之前的函数前向运算与矩阵,我们以一个动态图片直观的看一下前向运算过程:
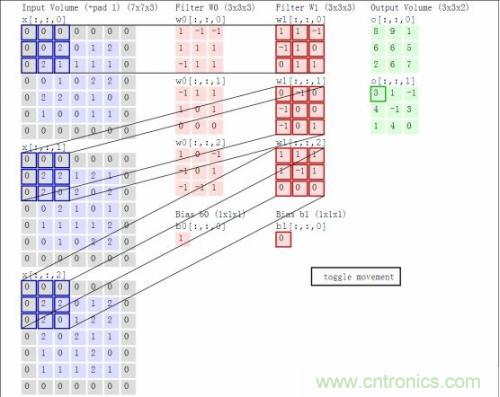
这里卷积核大小与移动的步长stride、输出深度决定了下一层网络的大小。同时,核大小与stride步长在导致上一层矩阵不够大时,需要用padding来补0(如上图灰色的0)。以上就叫做卷积运算,这样的一层神经元称为卷积层。上图中W0和W1表示深度为2。
CNN卷积网络通常在每一层卷积层后加一个激励层,激励层就是一个函数,它把卷积层输出的数值以非线性的方式转换为另一个值,在保持大小关系的同时约束住值范围,使得整个网络能够训练下去。在人脸识别中,通常都使用Relu函数作为激励层,Relu函数就是max(0,x),如下所示:
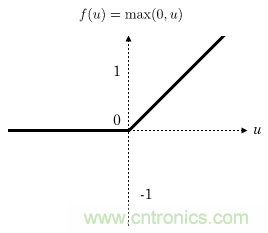
可见 Relu的计算量其实非常小!
CNN中还有一个池化层,当某一层输出的数据量过大时,通过池化层可以对数据降维,在保持住特征的情况下减少数据量,例如下面的4*4矩阵通过取最大值降维到2*2矩阵:
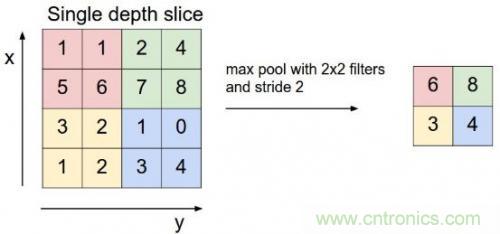
上图中通过对每个颜色块筛选出最大数字进行池化,以减小计算数据量。
通常网络的最后一层为全连接层,这样一般的CNN网络结构如下所示:
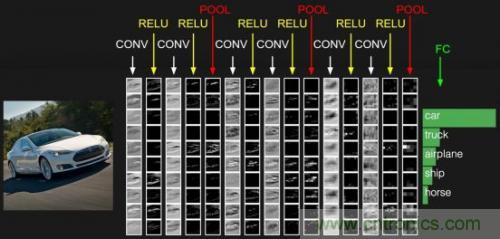
CONV就是卷积层,每个CONV后会携带RELU层。这只是一个示意图,实际的网络要复杂许多。目前开源的Google FaceNet是采用resnet v1网络进行人脸识别的,关于resnet网络请参考论文https://arxiv.org/abs/1602.07261,其完整的网络较为复杂,这里不再列出,也可以查看基于TensorFlow实现的Python代码https://github.com/davidsandberg/facenet/blob/master/src/models/inception_resnet_v1.py,注意slim.conv2d含有Relu激励层。
以上只是通用的CNN网络,由于人脸识别应用中不是直接分类,而是有一个注册阶段,需要把照片的特征值取出来。如果直接拿softmax分类前的数据作为特征值效果很不好,例如下图是直接将全连接层的输出转化为二维向量,在二维平面上通过颜色表示分类的可视化表示:
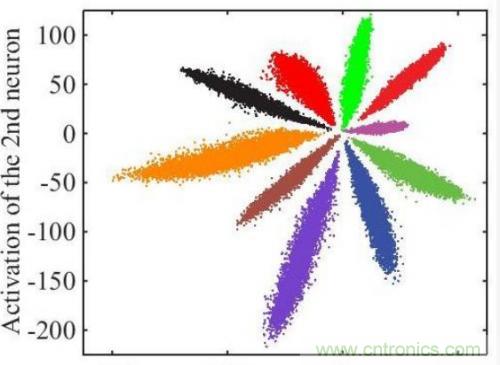
可见效果并不好,中间的样本距离太近了。通过centor loss方法处理后,可以把特征值间的距离扩大,如下图所示:

这样取出的特征值效果就会好很多。
实际训练resnet v1网络时,首先需要关注训练集照片的质量,且要把不同尺寸的人脸照片resize到resnet1网络首层接收的尺寸大小。另外除了上面提到的学习率和随机梯度下降中每一批batchsize图片的数量外,还需要正确的设置epochsize,因为每一轮epoch应当完整的遍历完训练集,而batchsize受限于硬件条件一般不变,但训练集可能一直在变大,这样应保持epochsize*batchsize接近全部训练集。训练过程中需要密切关注loss值是否在收敛,可适当调节学习率。
最后说一句,目前人脸识别效果的评价唯一通行的标准是LFW(即Labeled Faces in the Wild),它包含大约6000个不同的人的12000张照片,许多算法都依据它来评价准确率。但它有两个问题,一是数据集不够大,二是数据集场景往往与真实应用场景并不匹配。所以如果某个算法称其在LFW上的准确率达到多么的高,并不能反应其真实可用性。

