

【导读】AI大模型迭代推动算力指数级增长,而存储带宽演进滞后,“存储墙”已成为限制AI系统能效的核心瓶颈——单节点高带宽需求与传统存储接口性能不足的矛盾突出,企业级存储吞吐瓶颈亟待突破。对此,奎芯科技(MSquare)依托集成电路IP技术积淀,推出ONFI 6.0标准PHY IP解决方案,以优异传输、信号处理及适配能力破解存取鸿沟,并借Chiplet布局升级为基础设施平台,为AI存储降本增效提供新路径。
作为全球领先的集成电路IP供应商,奎芯科技已实现对ONFI 6.0标准的全面支持,旨在破解大数据时代的存取鸿沟。
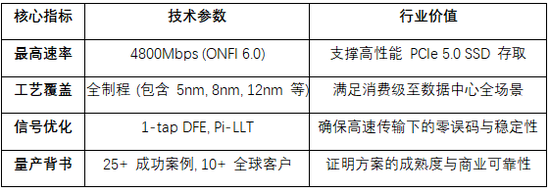
极致传输速率:支持最高 4800Mbps(符合NV-LPDDR4标准),显著提升闪存控制器与颗粒间的交互效率。
信号稳健性技术:内置 1-tap DFE(判决反馈均衡) 和 Pi-LLT技术,有效补偿高速信道中的损耗与衰减。
智能化适配能力:支持 8组Timing Group 及 SCA(独立指令地址)架构,具备基于固件的训练能力,能够完美适配全球主流厂商的存储颗粒。
技术规格参数
战略演进:从单一IP向Chiplet基础设施平台跨越
奎芯科技不仅提供“设计蓝图”,更通过 M2LINK 系列产品(如 ML100 IO Die)实现硬件级交付。
解耦架构:将存储接口与核心SoC物理解耦,弱化热效应对存储颗粒的影响,提升系统可靠性。
降本增效:通过国产化供应链和先进互联架构,助力客户降低约 20% 的系统级成本。
总结
针对AI“存储墙”痛点,奎芯科技以ONFI 6.0 PHY IP为突破,凭借4800Mbps传输速率、先进信号技术及适配能力,打破存储与计算性能壁垒,为大模型场景提供高效存取方案。奎芯科技未止步于单一IP,顺应Chiplet趋势,通过M2LINK系列实现硬件交付,以解耦架构提效、国产化供应链降本,完成从“设计蓝图”到“落地产品”的跨越。


